

Web scraping is a type of data harvesting from websites to inform market research for eCommerce brands. Web scraping is a fast, cost-effective way to gather data from across large websites or many websites and is important for retailers who want to optimize their eCommerce website and offerings. Python is popular for web scraping due to its versatility as a language, ease of use and extensive libraries — including those in web scraping.
Why Is Web Scraping Important For eCommerce?
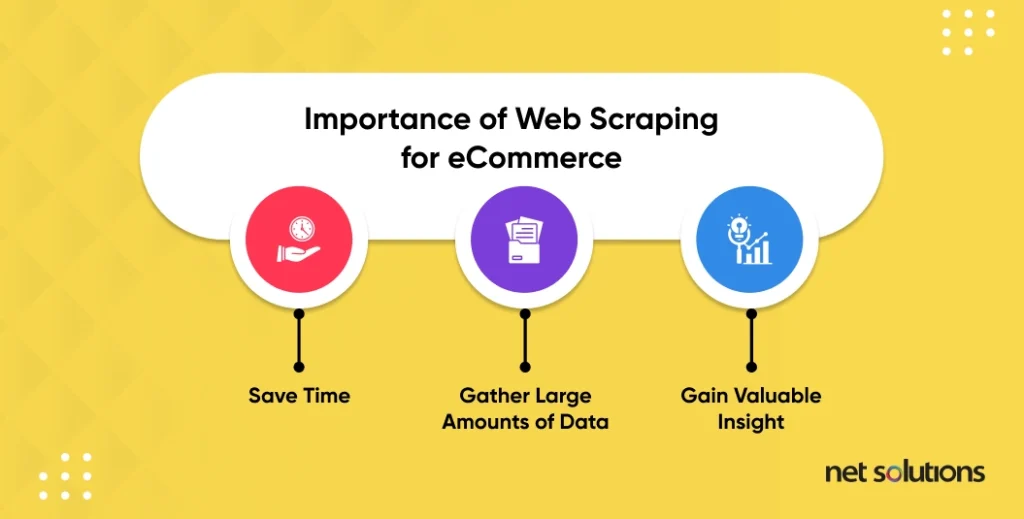
Web scraping extracts valuable data from the web into another usable format such as a spreadsheet or database, allowing brands to gather large amounts of information quickly.
What is the main purpose of web scraping?
Web scraping is important in eCommerce for research, to find leads and to inform decision-making. For e-Commerce, it is valuable to monitor competitor pricing and product offerings, customer sentiment, advertising and general market research.
Read on for a more detailed examination of the question, ‘What is the importance of web scraping in e-commerce?”

We respect your privacy. Your information is safe.
What is Python Web Scraping?
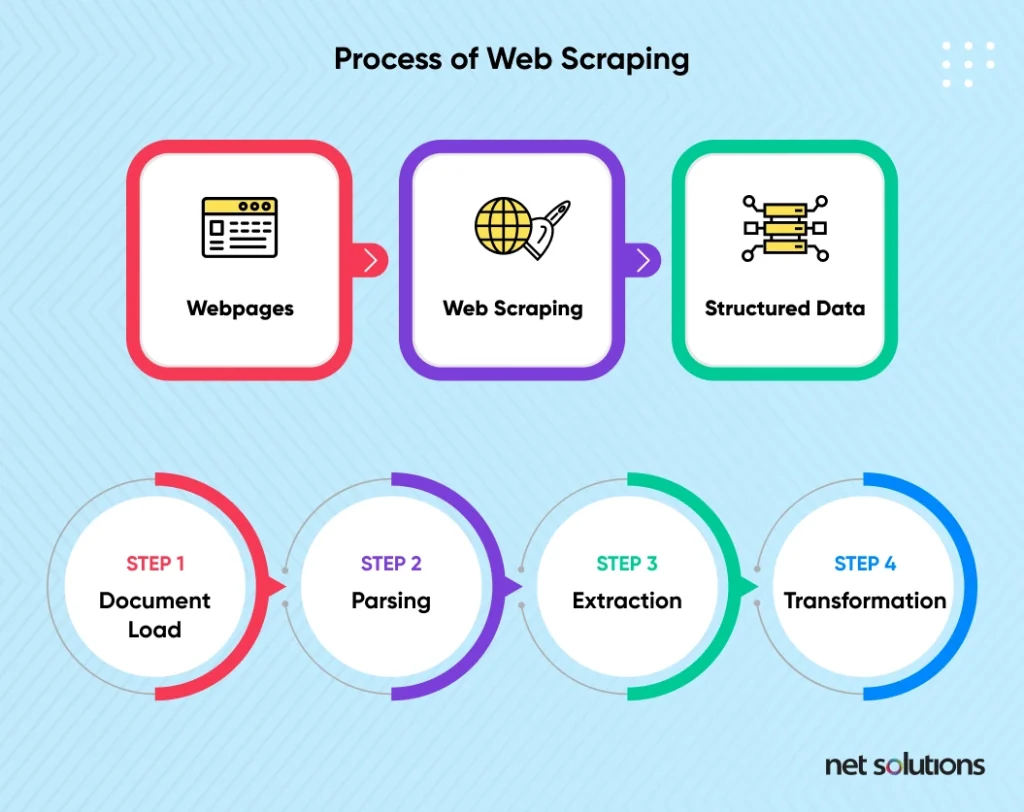
The use of the Python language and its associated libraries and frameworks to support web scraping. Python is currently the most popular programming language, known as an easy language with wide-reaching capabilities for software development, including web scraping.
Advantages Of Using Python For Web Scraping In eCommerce?
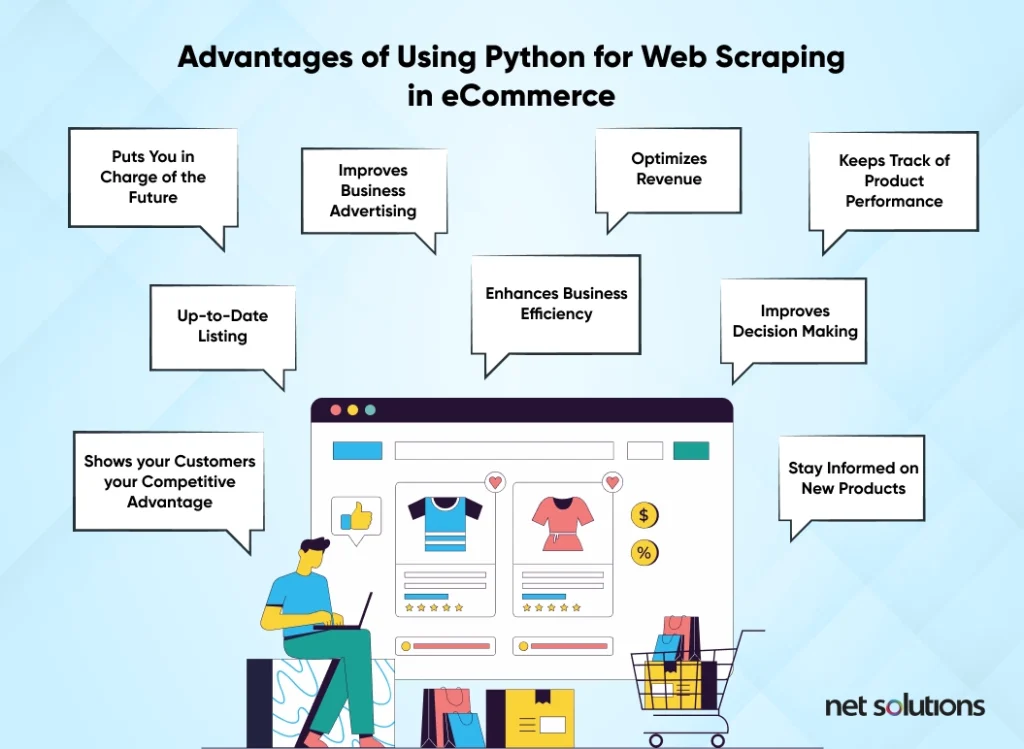
What is the advantage of using Python for web scraping? The benefits of Python for web scraping are:
- Easy:
- Libraries & frameworks:
- Large community of support:
- Established data collector:
- Great with large volumes of data:
Python is simple, versatile and fast to develop, debug or customize. It is a well-known and popular language requiring minimal code (thanks dynamic typing!) to achieve end results.
There are extensive frameworks & libraries, including those for web scraping (read on for more)
Having well-established online communities makes it easier to refer to resources or ask questions about Python or data scraping tools.
Data collection is a mainstream activity used by even the largest of companies (Google!), whose search engine (i.e. web scraper) is based on Python.
Python is known for its abilities to handle data and its math / data analysis libraries. (Yes, you can use machine learning on your web scraping results!)
How Can eCommerce Companies Benefit from Python Web Scraping?
Python is a practical solution suited to web scraping, but let’s examine what is the importance of web scraping in e-Commerce and e-marketing.
Why use eCommerce scraping?
What are the advantages and disadvantages of web scraping? Let’s start with the benefits of web scraping.
Organizations focused on digital commerce today face an increased competition and shifting consumer expectations around both product / service offering and online experience. Brands must continually invest in market research to stay ahead. Web scraping is a quick and effective tool for today’s needs, including:
Competitor price monitoring
Gather up-to-date information on competitor prices to react quickly to changes, understand the market and make informed pricing decisions. With additional tools, eCommerce retailers can even set up dynamic pricing to adjust prices in real-time based on competitor pricing or demand.
Monitor Product Performance & inform product research and development
Monitor product performance based on price, inventory levels and customer reviews and ratings to gain insight. For example, insight could include changing customer preferences, a need to alter or discontinue a product, or price changes to increase competitiveness.
Better Advertisements
Gather information about target audiences from other retailers, forums or social media and about competitor ad strategies to optimize advertising. When used on existing campaigns, web scraping can quickly compile A/B testing data across multiple paid platforms.
Future Trends Predictions
Identify emerging trends from news articles, blogs, social media and competitive websites about what consumers want or relevant trends (e.g. fashion colors for the season).
Improve Marketing Strategies
Gather large amounts of data on consumers, competitors, and market trends and extract intelligence (manually or with intelligence tools) to build out customer personas to inform future campaigns, generate new leads, personalize marketing, improve customer engagement strategies or find product influencers.
Competitor Analysis
Monitor competitors across multiple variables including products, product categories, pricing, ratings (product and brand), sale frequency, assortment and more. By looking at multiple competitors, information may reveal gaps in the market.
Consumer Sentiment Analysis
Understand customer reviews from across all brand properties (social media, storefront) and competitors (reviews, forum discussions) to understand customer emotions, wants, dislikes and feedback to inform product selection, product design, web design and more.
Inventory management
Extract catalog data to bring over to the website, including product information, sizing, color etc to help keep the inventory up to date and optimized.
Challenges and Risks of Python Web Scraping for eCommerce Stores
While there are many benefits to using web scraping of any kind, it is also true that web scraping can be abused or can be challenged by blocking.
Legal considerations
Web scraping is legal in the United States if the data is publicly available. However, note the type of data being scraped (public, personal or confidential), the purpose (research or illegal reuse), the how(publicly available vs abusing system exploits) and also the location (local laws).
Personally identifiable information (PII), copyrighted information or intellectual property are subject to strict regulation including the California Consumer Privacy Act (CCPA), the General Data Protection Regulation (GDPR) and regulations around data mining (e.g. the DSM Directive). The laws around ‘fair use’ and copyright also vary between countries.
Potential challenges and risks of web scraping for e-commerce stores
- Bot access: Content owners can opt out of scraping for some/all of the site by using a “Disallow” command in robots.txt.
- Captcha or Login: Some websites utilize a Captcha or a login to gate certain types of content or if too many requests are being made.
- Web structures: Complicated or constantly shifting web structures can make elements of the web scraper stop working. Further, the use of “+” and drop-downs (e.g. sizing or color details) make it difficult to capture all the data.
- Dynamic content: Dynamic pages that involve JavaScript or video content are not easily readable by many scraper tools.
- IP blocking or limiting: Some websites may block or impose a limit on actions per IP address to restrict scraping.
- Load speed: Due to the content of the site or the number of requests, the load speed may cause the scraper to fail.
Ways to mitigate risks and challenges
The best way to avoid the risks and challenges with web scraping is to be an ethical web scraper: only scrape what is allowed and respect the limits that a website places on scraping. Further, to avoid any limits or triggers, reduce the number of requests or have random interval times between requests to avoid looking like a negative ‘bot.’
Examples of Python web scraping applications in eCommerce
Case study 1: Product data extraction for online retailer
An online retailer product page has a lot of information that takes time to gather manually: product name, description, price, size, colors, reviews and availability. Web scraping can quickly gather this information and export it in a more usable and organized format.
Case study 2: Price monitoring for eCommerce platform
If a competitor suddenly has a sale or decides to drop a price even by a small percentage, your sales can quickly suffer. With real-time monitoring and alerts, or dynamic pricing integration, you can adjust in line with the competition.
Case study 3: Competitor analysis for fashion retailers
Fashion moves quickly. Gather data on competitor product offerings, colors, new products, and reviews to see what consumers are resonating with and make data-driven decisions about how to respond.
Web scraping with Python: top tools

To embark on the journey to web scraping using Python, consider these tools:
- Requests: A Python HTTP client package for making HTTP requests, to be used with another tool like Beautiful Soup.
- Beautiful Soup: A library to pull data out of HTML and XML files into a tree format to make it easier to browse and explore.
- Scrapy: A library good for web scraping, data mining and ongoing monitoring (great for competitive analysis).
- Selenium: Powerful for dynamic JavaScript pages or logging into social media, leveraging a WebDriver module to carry out scraping.
- LXML: A powerful library for parsing HTML and XML.
- Urllib3:
HTTP client to extract data from HTML or URLs.
How Can Net Solutions Help You Leverage Python For Web-Scraping?
Net Solutions Python development teams work closely with you to choose the right web scraping tools or to create a tool to do exactly what you want. Learn more by reading our retail and eCommerce case studies.
Frequently Asked Questions
While R excels in data manipulation and analysis, Python is more flexible in terms of the number of libraries and frameworks dedicated to web scraping. Contact us if you would like expert advice.
There is no single API specifically designed for web scraping, as web scraping can be achieved using various techniques and libraries.
There are several kinds of web scraping, but in general we have static web scraping that download static web content and parse it to extract data or dynamic web scraping for websites that are dynamic (e.g. use AJAX, JavaScript).
When it comes to e-Commerce, it’s important to choose the right tool for the need. Our favorites (from above) to work with are –
- Requests
- Beautiful Soup
- Scrapy
- Selenium
- LXML
- Urllib3

